PPO算法-chapter5-蒙特卡洛方法
PPO算法-chapter5-蒙特卡洛方法
Bohao Zhao[chapter-5]-蒙特卡洛方法
[PPO 算法]-一种model-free的方法-蒙特卡洛方法
前言
老规矩,先给出一个示例:抛硬币问题
结果(正面或反面)表示为随机变量
- 如果结果是正面,则
- 如果结果是反面,则
目标是计算
方法1:使用模型
假设已知概率模型为
根据定义
问题:可能无法知道精确的分布!
方法2:无模型或称为模型无关
想法:多次抛硬币,然后计算结果的平均值。
假设我们得到一个样本序列:
。那么均值可以近似为
这就是蒙特卡洛估计的思想!
数学依据
大数定律
对于一个随机变量
,假设 是一些独立同分布(iid)样本。令 为样本的平均值。那么,
因此,
是 的无偏估计,并且其方差随着 增加到无穷大而趋近于零。
MC算法介绍
回顾策略迭代步骤
策略迭代在每次迭代中有两个步骤:
- 策略评估:
- 策略改进:
策略改进步骤的逐元素形式是:
关键是计算
从model-based到model-free
两种动作值的表达式:
- 表达式1 需要模型:
- 表达式2 不需要模型:
实现无模型强化学习的构想:我们可以使用表达式2
基于数据(样本或经验)获得
如何基于数据获得
从
开始,遵循策略 ,生成一个episode。 该情节的回报是
,这是 在 中的一个样本。 假设我们有一组情节,因此
。那么,
基本思想:当模型不可用时,我们可以使用数据。
MC算法
给定一个初始策略
步骤1:策略评估。此步骤旨在估计所有
的 。具体来说,对于每个 ,运行足够多的情节。其回报的平均值,记为 ,用于近似 。 - 策略迭代算法的第一步通过首先求解贝尔曼方程中的
来计算 。这需要模型。 - MC 基本算法的第一步是直接从经验样本中估计
。这不需要模型。
- 策略迭代算法的第一步通过首先求解贝尔曼方程中的
步骤2:策略改进。此步骤旨在求解
对于所有 。贪婪最优策略是 ,其中 。 - 此步骤与策略迭代算法的第二步完全相同。
伪代码:MC 基本算法(策略迭代的无模型变体)
初始化:初始猜测
。 目标:搜索最优策略。
对于第
次迭代( ),执行以下操作: 对于每个状态
,执行以下操作: 对于每个动作
,执行以下操作: 收集足够多的从
开始,遵循 的情节。 策略评估:
策略改进:
如果
,则 ,否则
- MC 基本算法是策略迭代算法的一种变体。
- 无模型算法是基于有模型算法构建的。因此,在研究无模型算法之前,首先需要理解有模型算法是必要的。
- MC 基本算法有助于揭示基于蒙特卡洛(MC)的无模型强化学习的核心思想,但由于效率低,并不实用。
- 为什么 MC 基本算法估计动作值而不是状态值?这是因为状态值不能直接用于改进策略。当模型不可用时,我们应直接估计动作值。
- 由于策略迭代是收敛的,给定足够多的episode后,MC 基本算法的收敛性也得到保证。
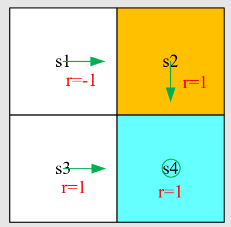
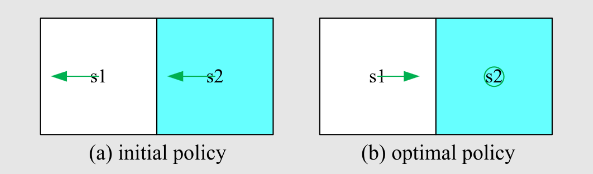
实例
任务:
- 图中显示了初始策略。
- 使用 MC 基本算法找到最优策略。
- 奖励设置为
。
步骤1 - 策略评估:
由于当前策略是确定性的,一个episode足以获得动作值!否则,如果策略或模型是随机的,则需要多个episode
从
开始,情节是 。因此,动作值是 从
开始,情节是 。因此,动作值是 从
开始,情节是 。因此,动作值是 从
开始,情节是 。因此,动作值是 从
开始,情节是 。因此,动作值是
步骤2 - 策略改进:
通过观察动作值,我们看到
是最大值。
因此,策略可以改进为
无论如何,
MC Exploring Starts算法
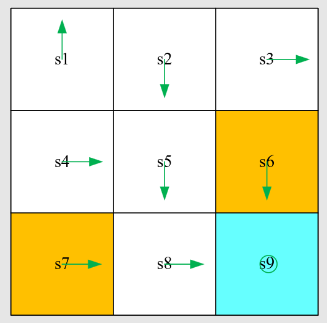
考虑一个网格世界示例,遵循策略
,我们可以得到一个情节,例如 访问:每次状态-动作对在情节中出现时,称为对该状态-动作对的访问。
使用数据的方法:初始访问方法
- 仅计算回报并近似
。 - 这是 MC 基本算法所做的。
- 缺点:未充分利用数据。
- 仅计算回报并近似
数据高效方法:
- 首次访问方法
- 每次访问方法
在基于蒙特卡洛(MC)的强化学习中,更新策略的另一个方面是何时更新策略。有两种方法:
第一种方法是在策略评估步骤中,收集所有从状态-动作对开始的episode,然后使用平均回报来近似动作值。
- 这是 MC 基本算法采用的方法。
- 这种方法的问题是智能体必须等待所有episode收集完毕。
第二种方法使用单个episode的回报来近似动作值。
- 这样,我们可以逐episode改进策略。
第二种方法会导致问题吗?
- 可以说单个情节的回报不能准确近似相应的动作值。
- 事实上,在上一章介绍的截断策略迭代算法中已经做到了这一点!
广义策略迭代:
- 不是特定算法。
- 它指的是在策略评估和策略改进过程之间切换的一般思想或框架。
- 许多强化学习算法属于此框架。
算法:MC 探索起始(MC 基本算法的高效变体)
初始化:初始策略
和所有 的初始值 。 和 对于所有 。 目标:搜索最优策略。
对于每个情节,执行以下操作:
情节生成:选择一个起始状态-动作对
并确保所有对都可以被选择(这是探索起始条件)。遵循当前策略,生成长度为 的情节: 。每个情节初始化 。 对于情节的每一步,
,执行以下操作:
策略评估:
策略改进:
如果
,则 ,否则
MC
什么是软策略?
- 如果采取任何动作的概率为正,则策略为软策略。
- 确定性策略:例如,贪婪策略
- 随机策略:例如,软策略
为什么引入软策略?
- 使用软策略,一些足够长的情节可以访问每个状态-动作对。
- 这样,我们不需要从每个状态-动作对开始的情节数量大。
- 因此,可以移除探索起始条件可以被移除。
- 我们将使用什么软策略?答案:
-贪婪策略-避免陷入局部最优,鼓励探索 - 什么是
-贪婪策略?
其中
例如:如果
,则
选择贪婪动作的机会总是大于其他动作,因为
当
时,它变得贪婪!
更多的利用但更少的探索。
当
时,它成为均匀分布。
更多的探索但更少的利用。
如何将
最初,MC 基本算法和 MC 探索起始中的策略改进步骤是解决
其中
其中
现在,策略改进步骤改为解决
其中
总结:
- MC
-贪婪与 MC 探索起始相同,只是前者使用 -贪婪策略。 - 不需要探索起始,但仍需以不同形式访问所有状态-动作对。
算法:MC
-贪婪(MC 探索起始的变体) 初始化:初始策略
和所有 的初始值 。 和 对于所有 。 目标:搜索最优策略。
对于每个情节,执行以下操作:
情节生成:选择一个起始状态-动作对
(不需要探索起始条件)。遵循当前策略,生成长度为 的情节: 。每个情节初始化 。 对于情节的每一步,
,执行以下操作:
策略评估:
策略改进:
令
且