PPO算法-chapter7-时序差分算法
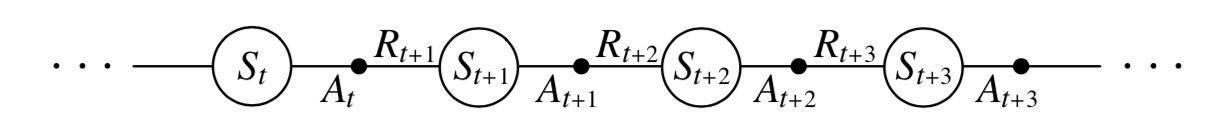
PPO算法-chapter7-时序差分算法
Bohao Zhao[chapter-7]-时序差分算法
需要注意的是
[PPO算法]-TD-时序差分算法
前言
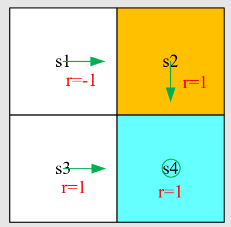
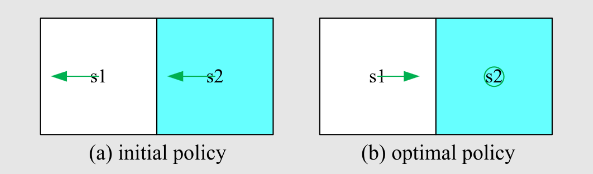
我们接下来考虑一些随机问题,并展示如何使用 RM 算法来解决它们。
首先,重新审视均值估计问题:基于一些独立同分布样本
我们上节课已经研究过这个问题。
- 通过写出
,我们可以将问题重新表述为一个求根问题
- 由于我们只能获得
的样本 ,噪声观测值为
- 根据上节课的内容,我们知道解决
的 RM 算法是
其次,考虑一个稍微复杂的问题。即基于
- 为了解决这个问题,我们定义
- 然后,问题变为一个求根问题:
。相应的 RM 算法是
第三,考虑一个更复杂的问题:计算
其中
- 假设我们可以获得
和 的样本 和 。我们定义
- 然后,问题变为一个求根问题:
。相应的 RM 算法是
这个算法看起来像后面展示的 TD 算法。
TD之状态值
问题陈述:
- 给定策略
,目标是在策略 下估计状态值 。 - 经验样本:
或 由 生成。
重要符号:
TD 学习算法
其中
这里,
- 在时间
,只有访问过的状态 的值会被更新,而未访问的状态 的值保持不变。 - 当上下文清晰时,(2) 中的更新将被省略。
TD 算法可以被注释为
其中
- 新估计值:
- 当前估计值:
- TD 目标
: - TD 误差
:
这里,
观察:新估计值
首先,为什么
这是因为算法驱动
为了证明这一点,
由于
因此,
这意味着
第二,TD 误差的解释是什么?
- 它反映了两个时间步之间的差异。
- 它反映了
和 之间的差异。为了说明这一点,记
注意
- 如果
,那么 应该为零(在期望意义上)。 - 因此,如果
不为零,那么 不等于 。 - TD 误差可以被解释为创新,这意味着从经验
中获得的新信息。
其他性质:
- TD 算法仅估计给定策略的状态值。
- 它不估计动作值。
- 它不搜索最优策略。
- 这个算法将在本次讲座中扩展为估计动作值,然后搜索最优策略。
- TD 算法 (3) 是理解更复杂 TD 算法的基础。
TD算法推导
这个 TD 算法在数学上做了什么?
它是一个无模型算法,用于解决给定策略
首先,贝尔曼方程的新表达式。
策略
其中
其中
上述方程是贝尔曼方程的另一种表达式。它有时被称为贝尔曼期望方程,是设计和分析 TD 算法的重要工具。
其次,使用 RM 算法解决方程 (5) 中的贝尔曼方程。具体来说,通过定义
我们可以将 (5) 重写为
由于我们只能获得
因此,解决
其中
RM 算法 (6) 看起来与 TD 算法非常相似。然而,有两个区别:
区别 1:RM 算法需要
对于 。 - 修改:
被更改为 ,以便算法可以利用一个 episode 中的顺序样本。
- 修改:
区别 2:RM 算法需要
。 - 修改:
被替换为估计值 。
- 修改:
通过上述修改,RM 算法变为 TD 算法。
定理(TD 学习的收敛性)
根据 TD 算法 (1),
以概率 1 收敛到 对于所有 随着 ,如果 且 对于所有 。
该定理表明,对于给定策略
,TD 算法可以找到状态值。 和 必须对所有 成立。 对于条件
:在时间步 , - 如果
,则 ; - 如果
,则 。
因此,要求每个状态必须被访问无限次(或足够多次)。
- 如果
对于条件
:在实践中,学习率 通常被选为一个小常数。在这种情况下,条件 不再有效。当 是常数时,仍然可以证明算法在期望意义上收敛。
虽然 TD 学习和 MC 学习都是无模型的,但 TD 学习与 MC 学习相比有哪些优缺点?
| TD/Sarsa 学习 | MC 学习 |
|---|---|
| 在线:TD 学习是在线的。它可以在收到奖励后立即更新状态/动作值。 | 离线:MC 学习是离线的。它必须等到一个 episode 完全收集后才能进行。 |
| 连续任务:由于 TD 学习是在线的,它可以处理 both episodic 和 continuing 任务。 | 情节任务:由于 MC 学习是离线的,它只能处理具有终止状态的情节任务。 |
TD 学习与 MC 学习的比较
虽然 TD 学习和 MC 学习都是无模型的,但 TD 学习与 MC 学习相比有哪些优缺点?
| TD/Sarsa 学习 | MC 学习 |
|---|---|
| 自举法:TD 学习是自举的,因为值的更新依赖于该值的先前估计。因此,它不需要初始猜测。 | 非自举法:MC 不是自举的,因为它可以直接估计状态/动作值而不需要任何初始猜测。 |
| 低估计方差:TD 的估计方差低于
MC,因为随机变量较少。例如,Sarsa 需要 |
高估计方差:为了估计 |
TD 学习与 MC 学习的比较。
TD之Sarsa算法
首先,我们的目标是估计给定策略
假设我们有一些经验
其中
是 的估计值; 是依赖于 的学习率。
- 为什么这个算法被称为 Sarsa?这是因为算法的每一步都涉及
。Sarsa 是 state-action-reward-state-action 的缩写。 - Sarsa 与之前的 TD 学习算法之间的关系是什么?我们可以通过在 TD
算法中用动作值估计
替换状态值估计 来获得 Sarsa。因此,Sarsa 是 TD 算法的动作值版本。 - Sarsa 算法在数学上做了什么?Sarsa 的表达式表明它是一个解决以下方程的随机近似算法:
这是贝尔曼方程的另一种表达形式,以动作值表示。
定理(Sarsa 学习的收敛性)
根据 Sarsa 算法,
以概率 1 收敛到动作值 随着 对于所有 ,如果 且 对于所有 。
该定理表明,对于给定策略
伪代码:通过 Sarsa 进行策略搜索
对于每个 episode,执行以下步骤:
在
处根据 生成 。 如果
( )不是目标状态,则:
- 根据
收集经验样本 :通过与环境交互生成 ;根据 生成 。 更新
的 值:
更新
的策略:
- 如果
,则 ; - 否则
。
, 。
关于该算法的备注:
的策略在 更新后立即更新。这是基于广义策略迭代的思想。 - 策略是
-贪婪策略,而不是贪婪策略,以平衡利用和探索。
明确核心思想和复杂性:
- 核心思想很简单:即使用算法解决给定策略的贝尔曼方程。
- 复杂性出现在我们试图找到最优策略并有效工作时。
TD之n-step Sarsa
动作值的定义是
折扣回报
n-step sarsa
需要注意的是
- Sarsa 旨在解决
- MC 学习旨在解决
- 一种中间算法称为
步 Sarsa 旨在解决
步 Sarsa 的算法是
- 当
时, 步 Sarsa 变为 (一步) Sarsa 算法。 - 当
时, 步 Sarsa 变为 MC 学习算法。
- 数据:
步 Sarsa 需要 。 - 由于
在时间 尚未收集,我们无法在步骤 实施 步 Sarsa。我们需要等到时间 才能更新 的 值:
由于
步 Sarsa 包括 Sarsa 和 MC 学习作为两个极端情况,其性能是 Sarsa 和 MC 学习的混合: - 如果
较大,其性能接近 MC 学习,因此方差较大但偏差较小。 - 如果
较小,其性能接近 Sarsa,因此由于初始猜测导致的偏差较大且方差相对较小。
- 如果
最后,
步 Sarsa 也用于策略评估。它可以与策略改进步骤结合,以搜索最优策略。
TD之Q-learning
Q-学习算法是
Q-学习与 Sarsa 非常相似。它们仅在 TD 目标方面有所不同:
- Q-学习中的 TD 目标是
- Sarsa 中的 TD 目标是
Q-学习在数学上做了什么?
它旨在解决
这是以动作值表示的贝尔曼最优方程。证明见我的书。
因此,Q-学习可以直接估计最优动作值,而不是给定策略的动作值。
在进一步研究 Q-learning 之前,我们先介绍两个重要概念:同策略(on-policy)学习 和 异策略(off-policy)学习。
在一个 TD 学习任务中存在两个策略:
- 行为策略(behavior policy) :用于生成经验样本;
- 目标策略(target policy) :不断被更新以趋近于最优策略。
同策略 vs 异策略:
- 当行为策略与目标策略相同时,这种学习称为同策略学习;
- 当它们不同时,称为异策略学习。
异策略学习的优势:
- 它可以基于任意其他策略生成的经验样本,来搜索最优策略。
- 例如:行为策略可以是探索性的,从而生成访问每个状态-动作对足够多次的 episode。
如何判断一个 TD 算法是同策略(on-policy)还是异策略(off-policy)?
- 首先,看算法要解决什么数学问题(即目标函数或方程);
- 其次,看算法需要什么样的经验样本。
Sarsa 旨在通过求解以下方程来评估给定策略
: 其中
, , 。 蒙特卡洛(MC) 旨在通过求解以下方程来评估给定策略
: 其中样本由策略
生成。
Sarsa 和 MC 都是在线策略(on-policy)方法:
是行为策略(behavior policy) ,因为我们需要由 生成的经验样本来估计其动作值; 也是目标策略(target policy) ,因为它会被持续更新以趋近于最优策略。
Q-learning 是异策略(off-policy) 的。
第一,Q-learning 的目标是求解贝尔曼最优方程:
第二,算法形式为:
只需要样本
。 行为策略(behavior policy) 用于在
中选择 ,可以是任意策略(如 -贪婪策略),用于生成样本。 目标策略(target policy) 是贪婪策略,即
,用于更新 Q 值。
因此,Q-learning 中行为策略与目标策略不同,属于异策略学习。
伪代码:通过 Q-learning 进行策略搜索(同策略版本)
对于每个 episode,执行以下步骤:
如果
( )不是目标状态,执行以下操作:
根据
收集经验样本 :
- 根据
生成 ; - 通过与环境交互生成
。 更新
的 Q 值:
更新
的策略:
否则,结束 episode。
伪代码:通过 Q-learning 搜索最优策略(异策略版本)
目标:从由行为策略
生成的经验样本中,学习一个适用于所有状态的最优目标策略 。 对于每个由
生成的 episode ,执行以下步骤: 对于 episode 中的每一步
,执行以下操作:
更新
的 Q 值:
更新
的目标策略:
(注:此处的
表示确定性贪婪策略,即直接选择当前 Q 值最大的动作。)
总结
本讲介绍的所有算法都可统一写成:
其中
| 算法 | |
|---|---|
| Sarsa | |
| Q-learning | |
| 蒙特卡洛 |
注:若令