宇树G1强化学习训练与部署

宇树G1强化学习训练与部署
Bohao ZhaoROS 深蓝学院宇树机器人强化学习训练与部署
环境必备
深蓝学院的作业是基于宇树科技的官方强化学习文档进行布置的,里面的部署操作步骤也在官网有,这里给出宇树机器人的强化学习部署链接:
- https://support.unitree.com/home/zh/G1_developer/rl_control_routine
- https://support.unitree.com/home/zh/rl_gym/intro
- 系统要求
由于 isaac_gym 仿真平台需要 CUDA,本文建议硬件需要配置
NVIDIA 显卡(显存>8GB、
RTX系列显卡),并安装相应的显卡驱动。建议系统使用
ubuntu18/20,显卡驱动 525 版本。
这里最好使用 Ubuntu20.04 发行版
- 下载
miniconda
为了方便进行环境的隔离,这里本电脑早期已经完成了
miniconda
的相关包下载,这里直接按照链接步骤进行即可,在此不进行记录
- 创建强化学习环境
1 | $ conda create -n rl-g1 python=3.8 |
电脑配置为 4090 显卡,为了不和师弟的环境冲突,这里创建名为
rl-g1 的环境,指定创建环境时安装的 Python 版本为
3.8,如果不指定,会默认使用 conda 当前版本中默认的 Python
版本(可能是最新的)。
- 激活环境
1 | $ conda activate rl-g1 |
- 安装
CUDA、Pytorch
1 | $ pip3 install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio==0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html |
这里选择安装 PyTorch
的特定版本:1.10.0,+cu113 表示这个版本是编译给
CUDA 11.3 使用的(GPU 加速版本)
安装了与上述 PyTorch 兼容的图像处理库 torchvision
安装了与 PyTorch 兼容的音频处理库 torchaudio
注意,这里只是官网的步骤,后续出现报错不兼容问题,这行代码需要重新修改
- 下载 Isaac Gym
Preview 4 仿真平台,解压后进入
python目录,使用pip安装。
1 | $ # current directory: isaacgym/python |
- 运行
python/examples目录下的例程,验证安装是否成功。
1 | $ # current directory: isaacgym/python/examples |
实例运行成功标识
- 安装
rsl_rl库
1 | $ git clone https://github.com/leggedrobotics/rsl_rl |
- 下载宇树官方示例代码
1 | $ git clone https://github.com/unitreerobotics/unitree_rl_gym.git |
注意,这个示例代码在询问宇树科技的工程师后,对应的是实机遥控上常规运控模式
- 修改路径
修改 legged_gym/scripts/train.py ,
legged_gym/scripts/play.py
中的sys.path.append("/home/unitree/h1/legged_gym")
为自己的路径。
这个到手不知道具体怎么操作,暂时没管
- 开始训练
1 | $ cd legged_gym/scripts/ |
报错!!!
1 | Importing module 'gym_38' (/home/robot/RemoteUsers/Bohao/examples/rl-g1/IsaacGym_Preview_4_Package/isaacgym/python/isaacgym/_bindings/linux-x86_64/gym_38.so) |
这里显示没有名为 legged_gym
的包,可能是缺少相关环境变量的引入,也就是上一步修改路径的工作
- 导入环境变量
1 | $ cd ./rsl_rl/unitree_rl_gym |
根据询问 GPT 的结果,导入环境变量后重新运行训练例程
报错!!!
1 | # 最后一句 |
注意到这里报错的是 gpu 架构不对,说明之前的架构配置有问题,GPT 给出的答复为:
这说明 TorchScript/JIT 编译 GPU 相关 CUDA 扩展时,在调用
nvrtc(NVIDIA Runtime Compilation)的时候,传递的 GPU
架构参数无效。这是一个典型的 CUDA 版本与 GPU 驱动或 PyTorch/Isaac Gym
不兼容 的问题。
- 显示本电脑架构
1 | $ nvidia-smi |
输入命令后,命令行显示为
1 | nvcc: NVIDIA (R) Cuda compiler driver |
而我们之前安装官网安装的torch是 CUDA 11.3
版本,与目前本服务器电脑 4090 的 CUDA 版本 12.1 不兼容
- 卸载之前的
CUDA 11.3版本
1 | $ pip uninstall torch torchvision torchaudio |
- 重新安装兼容的
Pytorch
1 | $ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 |
这里安装 12.1 版本的最佳,和我们电脑匹配
模型训练
- 仿真训练参数选择
--task: 必选参数,值可选(go2, g1, h1, h1_2),这里 g1--headless: 默认启动图形界面,设为 true 时不渲染图形界面(效率更高)--resume: 从日志中选择 checkpoint 继续训练--experiment_name: 运行/加载的 experiment 名称--run_name: 运行/加载的 run 名称--load_run: 加载运行的名称,默认加载最后一次运行--checkpoint: checkpoint 编号,默认加载最新一次文件--num_envs: 并行训练的环境个数--seed: 随机种子--max_iterations: 训练的最大迭代次数--sim_device: 仿真计算设备,指定 CPU 为--sim_device=cpu--rl_device: 强化学习计算设备,指定 CPU 为--rl_device=cpu
- 运行训练脚本
1 | $ python3 legged_gym/scripts/train.py --task=g1 |
默认保存训练结果:logs/<experiment_name>/<date_time>_<run_name>/model_<iteration>.pt
- 开始训练(由于我们具有实物,最好保持示例参数不便,迭代 10000 次进行训练)

小 tip :图形界面渲染会导致训练速度减慢,在 IsaacGym
的界面中按键盘上的v键,可以暂停渲染,加快训练速度。如果想要查看训练的效果可以再次按v,重新开启渲染。
训练的时候犯蠢没看到这个,训练老慢了花了一天半。
- 训练结果展示-isaacgym
1 | $ python legged_gym/scripts/play.py --task=g1 |

注意,使用默认 play
脚本运行将加载实验文件夹上次运行的最后一个模型,可通过 load_run 和
checkpoint 指定其他模型。注意到,每进行 50
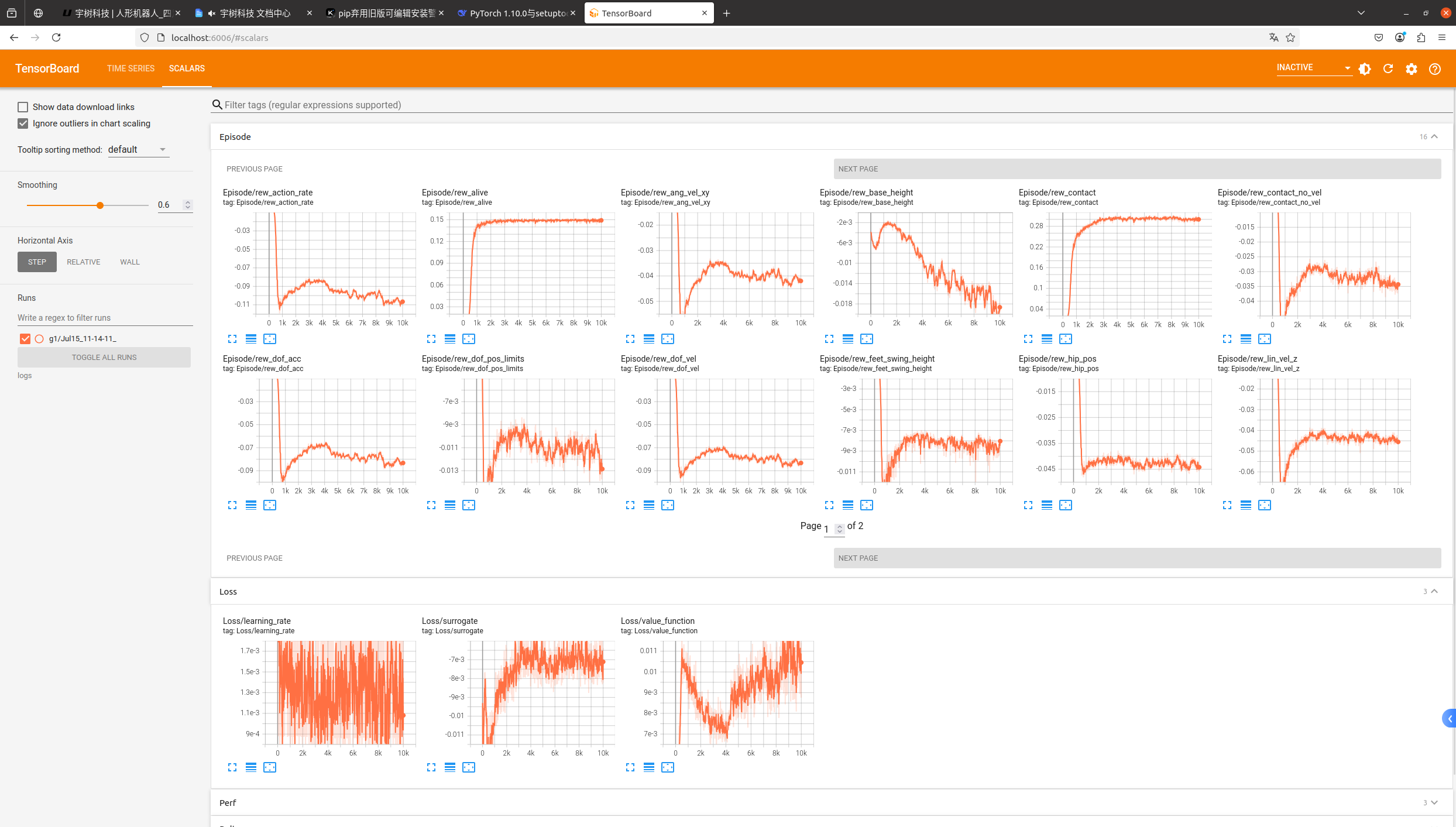
次迭代进行一次训练网络参数的模型保存,其中第一个事件文件记录模型训练过程中的相关性能参数,可以由可视化工具,如
TensorBoard 进行可视化展示。

- 训练结果文件
训练结果默认保存在
rsl_rl/unitree_rl_gym/logs/g1/exported/policies
文件夹下,第一次训练的官方例程名称为 policy_lstm_1.pt
TensorBoard数据可视化
安装 TensorBoard
1 | $ pip install tensorboard |
在 rsl_rl/unitree_rl_gym 文件夹下打开终端,切换到
rl-g1 的 conda 环境,运行
1 | $ tensorboard --logdir logs |
在本地打开网址 http://localhost:6006/ 查看训练过程可视化结果
模型部署
- sim2sim,部署到
mujoco
将训练结果文件 policy_lstm_1.pt 复制粘贴到
deploy_mujoco/configs/g1.yaml 中,对其内部的
policy_path: "{LEGGED_GYM_ROOT_DIR}/deploy/pre_train/g1/motion.pt"
的 motion.pt 控制策略进行替换,使用我们训练出来的控制策略
policy_lstm_1.pt
- 启动
python脚本并运行
1 | $ python deploy/deploy_mujoco/deploy_mujoco.py g1.yaml |

成功运行,机器人稳定行走